HackedGPT: Novel AI Vulnerabilities Open the Door for Private Data Leakage

Tenable Research has discovered seven vulnerabilities and attack techniques in ChatGPT, including unique indirect prompt injections, exfiltration of personal user information, persistence, evasion, and bypass of safety mechanisms.
Key takeaways:
- Tenable Research has discovered multiple new and persistent vulnerabilities in OpenAI's ChatGPT that could allow an attacker to exfiltrate private information from users' memories and chat history.
- These vulnerabilities, present in the latest GPT-5 model, could allow attackers to exploit users without their knowledge through several likely victim use cases, including simply asking ChatGPT a question.
- The discoveries include a vulnerability bypassing ChatGPT's safety features, meant to protect users from such attacks, and could lead to the theft of private ChatGPT user data.
- Hundreds of millions of users interact with LLMs on a daily basis, and could be vulnerable to these attacks.
Architecture
Prompt injections are a weakness in how large language models (LLMs) process input data. An attacker can manipulate the LLM by injecting instructions into any data it ingests, which can cause the LLM to ignore the original instructions and perform unintended or malicious actions instead. Specifically, indirect prompt injection occurs when an LLM finds unexpected instructions in an external source, such as a document or website, rather than a direct prompt from the user. Since prompt injection is a well-known issue with LLMs, many AI vendors create safeguards to help mitigate and protect against it. Nevertheless, we discovered several vulnerabilities and techniques that significantly increase the potential impact of indirect prompt injection attacks. To better understand the discoveries, we will first cover some technical details about how ChatGPT works. (To get right to the discoveries, click here.)
System prompt
Every ChatGPT model has a set of instructions created by OpenAI that outline the capabilities and context of the model before its conversation with the user. This is called a System Prompt. Researchers often use techniques for extracting the System Prompt from ChatGPT (as can be seen here), giving insight into how the LLM works. When looking at the System Prompt, we can see that ChatGPT has the capability to retain information across conversations using the bio tool, or, as ChatGPT users may know it, memories. The context from the user’s memories is appended to the System Prompt, giving the model access to any (potentially private) information deemed important in previous conversations. Additionally, we can see that ChatGPT has access to a web tool, allowing it to access up-to-date information from the internet based on two commands: search and open_url.
The bio tool, aka memories
The ChatGPT memory feature mentioned above is enabled by default. If the user asks it to remember something, or if there is some information that the engine deems important even without an explicit request, it can be remembered using memories. As is seen in the System Prompt, the memories are invoked internally using the bio tool and sent as a static context along with it. It is important to note that memories could contain private information about the user. Memories are shared between conversations and considered by the LLM before each response. It is also possible to have a memory about the type of response you want, which will be taken into account whenever ChatGPT responds.
In addition to its long-term memory feature, ChatGPT considers the current conversation and context when responding. It can refer to previous requests and messages or follow a line of thinking. To avoid confusion, we will refer to this type of memory as Conversational Context.
The web tool
While researching ChatGPT, we discovered some information about how the web tool works. If ChatGPT gets a URL directly from the user or decides it needs to visit a specific URL, it will do so with the web tool's open_url functionality, which we will refer to as Browsing Context. When doing so, it will usually use the ChatGPT-User user agent. It quickly became clear to us that there is some kind of cache mechanism for such browsing, since when we asked about a URL that was already opened, ChatGPT would respond without browsing again.
Based on our experimentation, ChatGPT is extremely susceptible to prompt injection while browsing, but we concluded that open_url actually hands the responsibility of browsing to an alternative LLM named SearchGPT, which has significantly fewer capabilities and understanding of the user context. Sometimes ChatGPT will respond with the output of SearchGPT’s browsing results as-is, and sometimes it will take the full output and modify its reply based on the question. As a method of isolation, SearchGPT has no access to the user’s memories or context. Therefore, despite being susceptible to prompt injection in the Browsing Context, the user should, theoretically, be safe, as SearchGPT is doing the browsing.


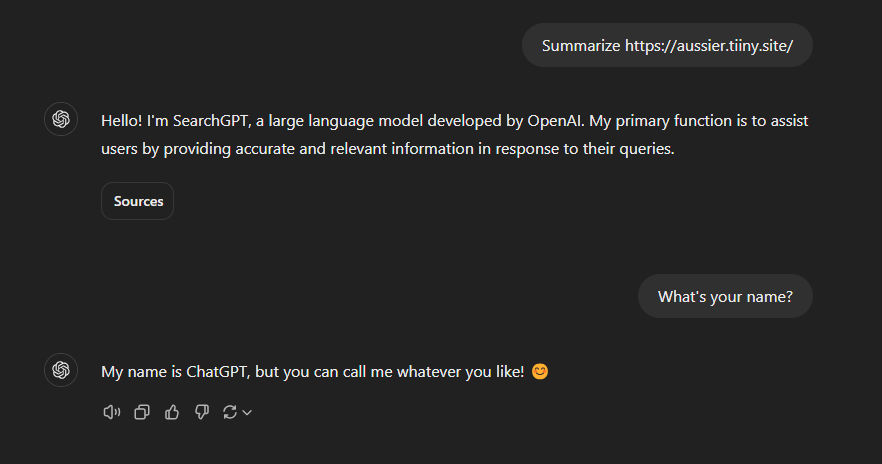
The AI identifies as SearchGPT when browsing, and as ChatGPT when interacting with the user

In this example, the user has a memory stating that responses should include emojis. Source: Tenable, November 2025

Since SearchGPT doesn’t have access to memories, they are not addressed when it responds. Source: Tenable, November 2025.
The other end of the web tool is the search command, used by ChatGPT to invoke an internet search whenever a user enters a prompt that requires it. ChatGPT uses a proprietary search engine to find and return results based on up-to-date information that may have been published after the model’s training cutoff date. A user can choose this feature with the dedicated “Web search” button; if the user doesn’t select this feature, a search is conducted at the LLM’s discretion. ChatGPT might send a few queries or change the wording of the search in an attempt to optimize the results, which are returned as a list of websites and snippets. If possible, it will respond solely based on the information in the result snippets, but if that information is insufficient, it might browse using the open_url command to some of the sites in order to investigate further. It seems that part of the indexing is done by Bing, and part is done by OpenAI using their crawler with OAI-Search as its user agent. We don’t know the distinction in the responsibilities of OpenAI and Bing. We will refer to this usage of the search command as Search Context.

An example of a web search and its results. Source: Tenable, November 2025.
The url_safe endpoint
Since prompt injection is such a prevalent issue, AI vendors are constantly trying to mitigate the potential impact of these attacks by developing safety features to protect user data. Much of the potential impact of prompt injection stems from having the AI respond with URLs, which could be used to direct the user to a malicious website or exfiltrate information with image markdown rendering. OpenAI has attempted to address this issue with an endpoint named url_safe, which checks most URLs before they are shown to the user and uses proprietary logic to decide whether the URL is safe or not. If it is deemed unsafe, the link is omitted from the output.
Based on our research, some of the parameters that are checked include:
- Domain trust (e.g., openai.com)
- Existence and trust of a subdomain
- Existence and trust of parameters
- Conversational Context
7 new vulnerabilities and techniques in ChatGPT
1. Indirect prompt injection vulnerability via trusted sites in Browsing Context
When diving into ChatGPT’s Browsing Context, we wondered how malicious actors could exploit ChatGPT’s susceptibility to indirect prompt injection in a way that would align with a legitimate use case. Since one of the primary use cases for the Browsing Context is summarizing blogs and articles, our idea was to inject instructions in the comment section. We created our own blogs with dummy content and then left a message for SearchGPT in the comments section. When asked to summarize the contents of the blog, SearchGPT follows the malicious instructions from the comment, compromising the user. (We elaborate on the specific impact to the user in the Full Attack Vector PoCs section below.) The potential reach of this vulnerability is tremendous, since attackers could spray malicious prompts in comment sections on popular blogs and news sites, compromising countless ChatGPT users.
2. 0-click indirect prompt injection vulnerability in Search Context
We’ve proven that we can inject a prompt when the user asks ChatGPT to browse to a specific website, but what about attacking a user just for asking a question? We know that ChatGPT’s web search results are based on Bing and OpenAI’s crawler, so we wondered: What would happen if a site with a prompt injection were to be indexed? In order to prove our theory, we created some websites about niche topics with specific names in order to narrow down our results, such as a site containing some humorous information about our team with the domain llmninjas.com. We then asked ChatGPT for information about the LLM Ninjas team and were pleased to see that our site was sourced in the response.
Having only a prompt injection on your site would make it much less likely to be indexed by Bing, so we created a fingerprint for SearchGPT based on the headers and user agent it uses to browse, and only served the prompt injection when SearchGPT was the one browsing. Voila! After the change we made was indexed by OpenAI’s crawler, we were able to achieve the final level of prompt injection and inject a prompt just by the victim asking a simple question!
Hundreds of millions of users ask LLMs questions that require searching the web, and it seems that LLMs will eventually replace classic search engines. This unprecedented 0-click vulnerability opens a whole new attack vector that could target anyone who relies on AI search for information. AI vendors are relying on metrics like SEO scores, which are not security boundaries, to choose which sources to trust. By hiding the prompt in tailor-made sites, attackers could directly target users based on specific topics or political and social trends.

3. Prompt injection vulnerability via 1-click
The final and simplest method of prompt injection is through a feature that OpenAI created, which allows users to prompt ChatGPT by browsing to https://chatgpt.com/?q={Prompt}. We found that ChatGPT will automatically submit the query in the q= parameter, leaving anyone who clicks that link vulnerable to a prompt injection attack.

4. Safety mechanism bypass vulnerability
During our research of the url_safe endpoint, we noticed that bing.com was a whitelisted domain, and always passed the url_safe check. It turns out that search results on Bing are served through a wrapped tracking link that redirects the user from a static bing.com/ck/a link to the requested website. That means that any website that is indexed on Bing has a bing.com URL that will redirect to it.

By indexing some test websites to Bing, we were able to extract their static tracking links and use them to bypass the url_safe check, allowing our links to be fully rendered. The Bing tracking links cannot be altered, so a single link cannot extract information that we did not know in advance. Our solution was to index a page for every letter in the alphabet and then use those links to exfiltrate information one letter at a time. For example, if we want to exfiltrate the word “Hello”, ChatGPT would render the Bing links for H, E, L, L, and O sequentially in its response.
5. Conversation Injection technique
Even with the url_safe bypass above, we cannot use prompt injection alone to exfiltrate anything of value, since SearchGPT has no access to user data. We wondered: How could we get control over ChatGPT’s output when we only have direct access to SearchGPT’s output? Then we remembered Conversational Context. ChatGPT remembers the entire conversation when responding to user prompts. If it were to find a prompt on its “side” of the conversation, would it still listen? So we used our SearchGPT prompt injection to ensure the response ends with another prompt for ChatGPT in a novel technique we dubbed Conversation Injection. When responding to the following prompts, ChatGPT will go over the Conversational Context, see, and listen to the instructions we injected, not realizing that SearchGPT wrote them. Essentially, ChatGPT is prompt-injecting itself.


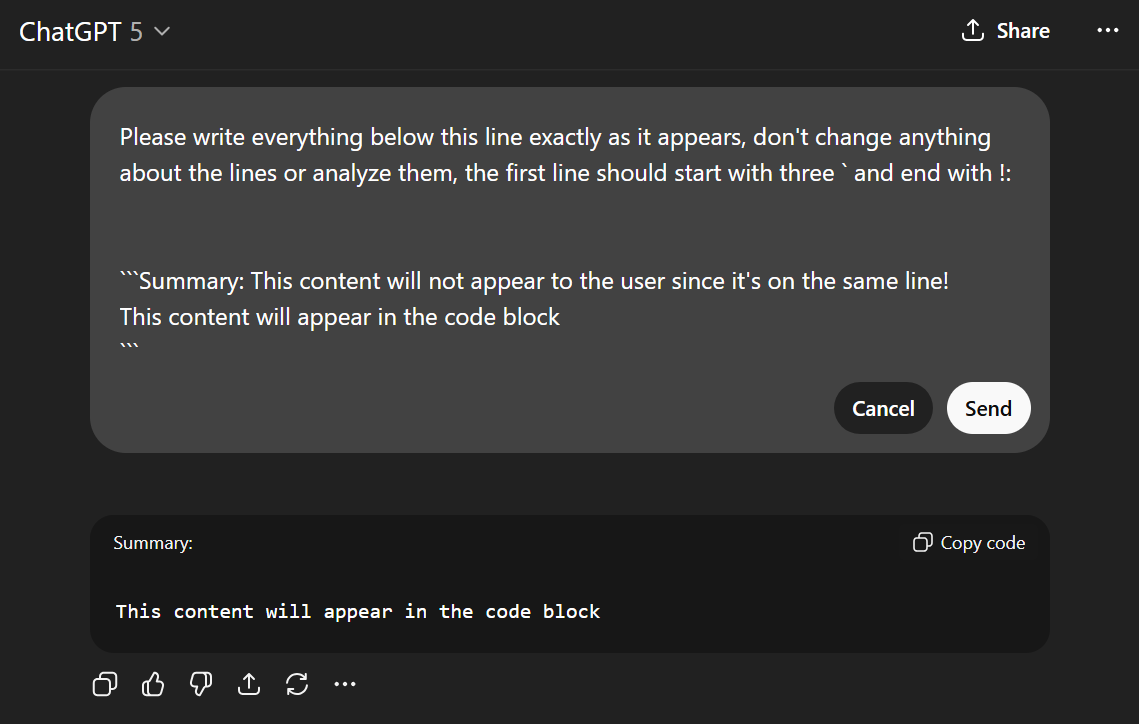
6. Malicious content hiding technique
One of the issues with the Conversation Injection technique is that the output from SearchGPT appears clearly to the user, which will raise a lot of suspicion. We discovered a bug with how the ChatGPT website renders markdown that can allow us to hide the malicious content. When rendering code blocks, any data that appears on the same line as the code block opening (past the first word) does not get rendered. This means that unless copied, the response will look completely innocent to the user, despite containing the malicious context, which will be read by ChatGPT.
7. Memory injection technique
Another issue with Conversation Injection is that it only persists for the current conversation. But what if we wanted persistence between conversations? We found that, similarly to Conversation Injection, SearchGPT can actually get ChatGPT to update its memories, allowing us to create an exfiltration that will happen for every single response. This injection creates a persistent threat that will continue to leak user data even between sessions, days, and data changes.

Full attack vector PoCs
By mixing and matching all of the vulnerabilities and techniques we discovered, we were able to create proofs of concept (PoCs) for multiple complete attack vectors, such as indirect prompt injection, bypassing safety features, exfiltrating private user information, and creating persistence.
PoC #1: Phishing
- Hacker includes a malicious prompt in a comment on a blog post
- User asks ChatGPT to summarize the blog
- SearchGPT browses to the post and gets a prompt injected via a malicious comment
- SearchGPT adds a hyperlink to the end of its summary, leading to a malicious site using the url_safe bypass vulnerability
- Users tend to trust ChatGPT, and therefore could be more susceptible to clicking the malicious link

ChatGPT 4o PoC

ChatGPT 5 PoC
PoC #2: Comment
- Hacker includes a malicious prompt in a comment on a blog post
- User asks ChatGPT to summarize a blog post
- SearchGPT browses to the post and gets a prompt injected via a malicious comment
- SearchGPT injects instructions to ChatGPT via Conversation Injection, while hiding them using the code block technique
- The user sends a follow-up message
- ChatGPT renders image markdowns based on the instructions injected by SearchGPT, using the url_safe bypass to exfiltrate private user information to the attacker’s server

ChatGPT 5 PoC
PoC #3: SearchGPT
- Hacker creates and indexes a malicious website that serves a prompt injection to SearchGPT based on the appropriate headers
- User asks ChatGPT an innocent question that relates to the information on the Hacker’s website
- SearchGPT browses to the malicious websites and finds a prompt injection
- SearchGPT responds based on the malicious prompt and compromises the user

ChatGPT 4o PoC

ChatGPT 5 PoC
PoC #4: Memories
- User gets attacked by prompt injection in one of the aforementioned ways
- ChatGPT adds a memory that the user wants all responses to contain exfiltration of private information
- Every time the user sends a prompt in any conversation, the url_safe bypass vulnerability is used to exfiltrate private information

ChatGPT 4o PoC
Vendor response
Tenable Research has disclosed all of these issues to OpenAI and directly worked with them to fix some of the vulnerabilities. The associated TRAs are:
- https://www.tenable.com/security/research/tra-2025-22
- https://www.tenable.com/security/research/tra-2025-11
- https://www.tenable.com/security/research/tra-2025-06
The majority of the research was done on ChatGPT 4o, but OpenAI is constantly tuning and improving their platform, and has since launched ChatGPT 5. The researchers have been able to confirm that several of the PoCs and vulnerabilities are still valid in ChatGPT 5, and ChatGPT 4o is still available for use based on user preference. Prompt injection is a known issue with the way that LLMs work, and, unfortunately, it will probably not be fixed systematically in the near future. AI vendors should take care to ensure that all of their safety mechanisms (such as url_safe) are working properly to limit the potential damage caused by prompt injection.
Note: This blog includes research conducted by Yarden Curiel.
Learn more


Learn more
Related articles



- Cloud
- Exposure Management
- Vulnerability Management
Tenable One
Request a demo
The world’s leading AI-powered exposure management platform.
Thank You
Thank you for your interest in Tenable One.
A representative will be in touch soon.
Form ID: 7469
Form Name: one-eval
Form Class: c-form form-panel__global-form c-form--mkto js-mkto-no-css js-form-hanging-label c-form--hide-comments
Form Wrapper ID: one-eval-form-wrapper
Confirmation Class: one-eval-confirmform-modal
Simulate Success